


Locking-Based Isolation at SQL Server
How SQL Server manages transactions concurrency by Isolation Levels, what are their anomalies, and how they work


Introduction
In the SQL world, a transaction is a unit of work that include single or multiple operations that query or modify data of a database, transforming the database from one consistent state to another.
To achieve this consistency and guarantee data integrity, transactions have four properties with the acronym ACID.
A glance at ACID properties
- Atomicity (A): Either all operations at the transaction take place successfully or none do.
- Consistency (C): The transaction transforms the database from one consistent state to another by controlling the level of isolation and adhering to the integrity rules defined within the database (like primary keys, foreign keys, and unique constraints).
- Isolation (I): Concurrent transactions can access only consistent data, in other words, transactions occur independently without interference, and that can be done by controlling the level of isolation.
- Durability (D): Modifications done by a successful transaction must be stored on permanent storage so they are persisted even if a system failure occurs.
In this article, we will focus on the Isolation property, how it works, its levels, and the anomalies that come as a cost for each level.
Isolation models (Pessimistic vs Optimistic concurrency control)
As we mentioned, database isolation enables transactions to occur independently without interference, so the question here is, how this can be achieved?
SQL Server has two models to achieve this isolation between transactions:
- Locking (Pessimistic): If the current state of data is inconsistent, readers are blocked (must wait) until the data becomes consistent.
- Row versioning (Optimistic): If the current state of data is inconsistent, readers get an older version of the consistent data so readers aren’t blocked (must not wait).
In this article, we will spotlight the locking-based (pessimistic concurrency control) model
Isolation locking modes
To know how the isolation mechanism works at SQL Server, you have to be familiar with two modes of locking:
- Exclusive: When a transaction modifies (update, delete, or insert) data, it requests an exclusive lock and if granted, this lock would be held until the transaction completes (the entire transaction). It is called “exclusive” because you can’t obtain an exclusive lock on a resource if this resource already has any lock mode; and if a resource already has an exclusive mode, no other lock mode can be obtained on this resource.
- Shared: When a transaction reads (select) data, it requests a shared lock, and it is released as soon as the read statement or the entire transaction is done (based on the isolation level). It is called “shared” because multiple transactions can have shared locks on a resource at the same time.
Take a look at the following table for more clarification, consider two transactions request different lock modes at the same resource:

Isolation levels
The isolation level is the level of data consistency when concurrent transactions deal with the same resource. The higher the isolation level the stricter the locks are and the longer the waiting time, and that means, the higher the isolation level, the higher the consistency is and the lower the concurrent transactions are.
The main goal of isolation levels is to control the following effects:
- Whether a reader requests a lock or not, and if so, how long the lock is held.
- If a transaction modifies (holds an exclusive lock) a resource and another reader wants to read the same resource, what is the reader behavior in this situation:
- Read the uncommitted data.
- Reads the last committed data.
- Blocked (wait) until the exclusive lock on the resource is released.
In fact, each database engine implements its isolation levels differently, but SQL Server supports six isolation levels, four levels are locking-based (READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE) and two levels are row-versioning-based (SNAPSHOT and READ COMMITTED SNAPSHOT).
Please remember these points before diving into the practical examples:
- Any anomaly that has been prevented at a lower isolation level won’t occur at a higher level.
- Any anomaly that has existed at a higher level, for sure will exist at a lower level.
- At all isolation levels, any writer has to request an exclusive lock to modify data which is released as soon as the entire transaction is done.
- For the single row, if you don’t start a transaction explicitly, it starts and commits implicitly.
To try these examples on your SQL Server database, please follow these steps:
- Create your own database (in my case called “isolation_db”)
Create the “users” table and insert this fake row
CREATE TABLE users (user_id INT PRIMARY KEY IDENTITY (1, 1), age INT NOT NULL); INSERT INTO users(age) VALUES (20);Open two connections to your database Con1 and Con2.
- Follow the steps shown in the images.
After you’re done at any of the below examples, commit any running transaction then run the following statements to cleanup:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- Reset to the default UPDATE users SET age = 20 WHERE user_id = 1; DELETE users WHERE age > 30;
Without further ado, let’s jump into the locking-based isolation levels from lowest to highest:
1- Read Uncommitted
How it works
This level is the lowest level of isolation in which a reader doesn’t ask for a shared lock to read data.
Anomalies it solves
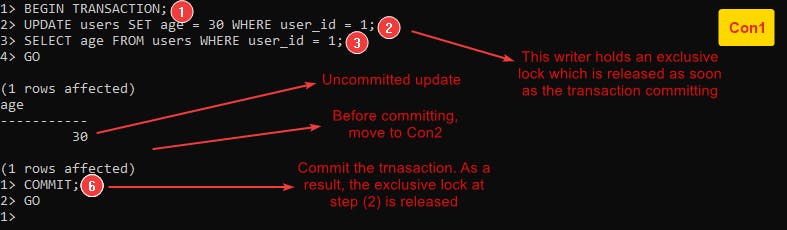
- Dirty Writes: It occurs in a situation if we have a transaction updates a resource and another transaction updates the same resource before the first completion.
This level can avoid this anomaly by the exclusive locks conflict. In other words, if a writer holds an exclusive lock, any other writer can’t obtain an exclusive lock simultaneously and must wait until the other exclusive lock is released.
Let’s jump into a practical example Example-1 to clarify how this level avoids dirty writing:


Anomalies it has
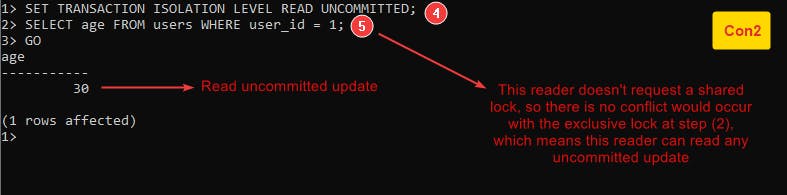
- Dirty Reads: It occurs in a situation if a transaction reads changes from another uncommitted transaction.
This anomaly occurs because this level doesn’t ask for a shared lock so there is no conflict with any writer having an exclusive lock which means the reader can read uncommitted changes.
Follow this example Example-2 :

2- Read Committed
How it works
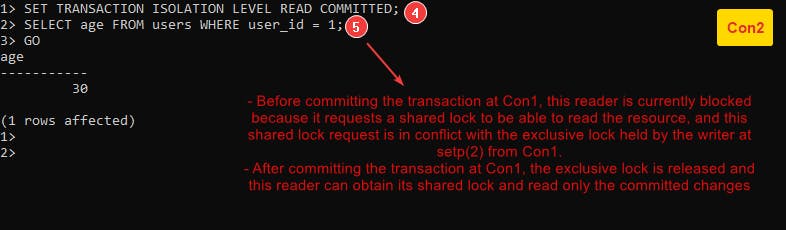
At this level, a reader must request a shared lock to read data which means if a writer holds an exclusive lock and a reader requests a shared lock, this request would conflict with the exclusive lock. The reader can get its shared lock once the writer commits the transaction. At that time, the reader reads only the committed changes.
Another important note you have to know is that a shared lock is released as soon as a reader (transaction statement) is done not the entire transaction.
This isolation level is the default level at SQL Server, you can get the isolation level option by running this statement DBCC useroptions;
Anomalies it solves
- Dirty Reads
Follow this example Example-3 :
Anomalies it has
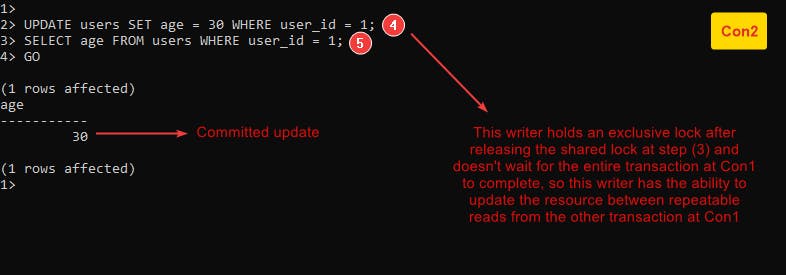
- Nonrepeatable reads: It occurs in a situation when a transaction reads the same resource multiple times and gets different results because it is changed by another committed transaction.
Because the fact that a shared lock at this level is released as soon as a transaction statement is done not the entire transaction, if we have two transactions, a second transaction can hold an exclusive lock on a resource (modify the resource) between multiple shared locks from the first transaction at the same resource.
Let’s clarify this anomaly by example Example-4 :

- Lost Update: It occurs in a situation where two transactions read a value, store what they read in memory, and then update a resource based on this stored value which means that the first transaction isn’t aware that the second transaction has already changed the resource value.
Because the fact that a shared lock at this level is released as soon as a transaction statement is done not the entire transaction, a reader can read a resource value, store it in memory, another transaction can obtain an exclusive lock and updates the resource as soon as releasing the shared lock at the first transaction.
If this explanation is not clear, please follow this example Example-5 :


3- Repeatable Read
How it works
At this level, a reader has to request a shared lock to read data, and this reader holds this lock until the end of the entire transaction (not only the statement like the read committed) which means if a reader holds a shared lock, there is no writer can obtain an exclusive lock to update this resource until releasing the shared lock by completing the transaction.
Anomalies it solves
- Nonrepeatable reads
Follow this example Example-6 :

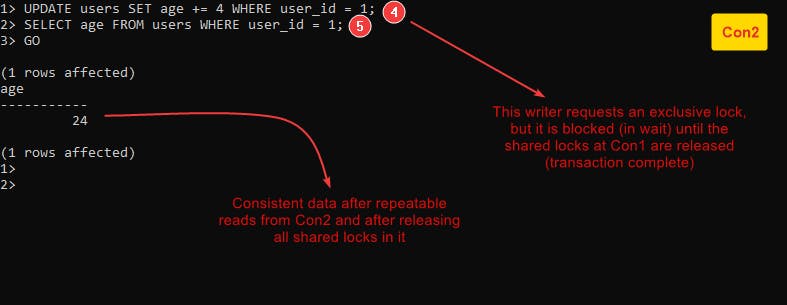
- Lost Update
Follow this example Example-7 :

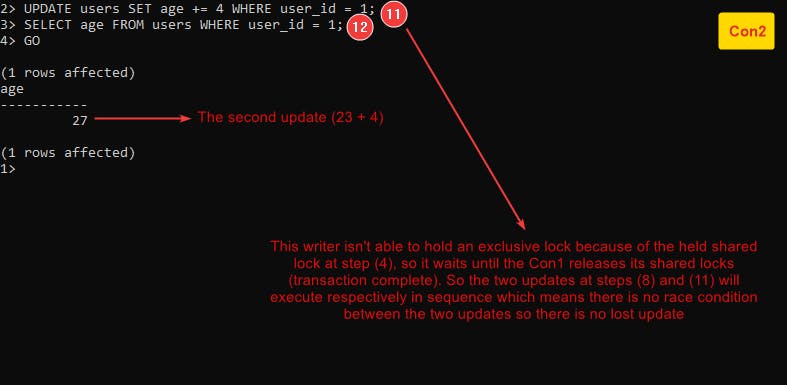
Anomalies it has
- Phantom Reads: A transaction only locks the rows it finds at the first query under a specific filter, not the rows that may be inserted by another transaction after this query and satisfy this filter. In other words, the second query in the first transaction will return new rows, and these rows are called phantoms.
If this explanation is not clear enough, please follow this example Example-8 :


4- Serializable
How it works
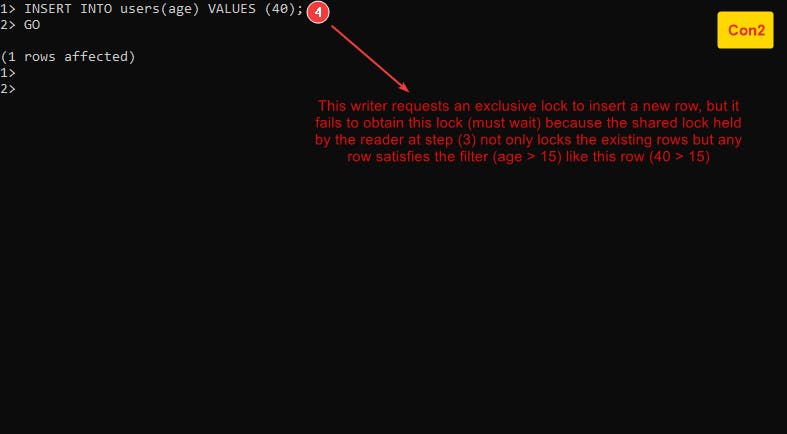
At this level, a reader has to request a shared lock to read data, and this reader holds this lock until the end of the entire transaction on top of that a reader locks any row that qualifies the query’s filter which means that the reader not only locks the already existing rows but also any rows may be inserted in the future satisfy the query’s filter by another transaction.
Anomalies it solves
- Phantom Reads
Let’s know how this level prevents the phantom rows by example Example-9 :

Check this summary table for the isolation levels and their anomalies

Which isolation level should you use
Unfortunately, there is no one size fits all solution, as we knew, the higher the isolation level you choose the lower the performance you get, the higher latency you have, and the lower throughput you have. So you shouldn’t choose the serializable level blindly because perfection usually comes at a cost.
As a first step, you should know the nature of your application and what anomalies it would face, and based on that you can decide which isolation level you choose.
Conclusion
In this article, we have known how SQL Server controls the concurrency between transactions, how you can control the level of data consistency by choosing the level of isolation, and the anomalies of every isolation level.
Resources
- T-SQL Fundamentals 3rd
- Understanding isolation levels
- Practical Guide to SQL Transaction Isolation